

Cloud cost optimization is no longer an engineering concern. It is a structural business issue.
Global cloud spending crossed $700 billion in 2025. Nearly 27% of that is wasted, according to Flexera. McKinsey estimates that organizations can recover 20–30% of cloud costs through disciplined optimization.
Yet most organizations fail to realize this.
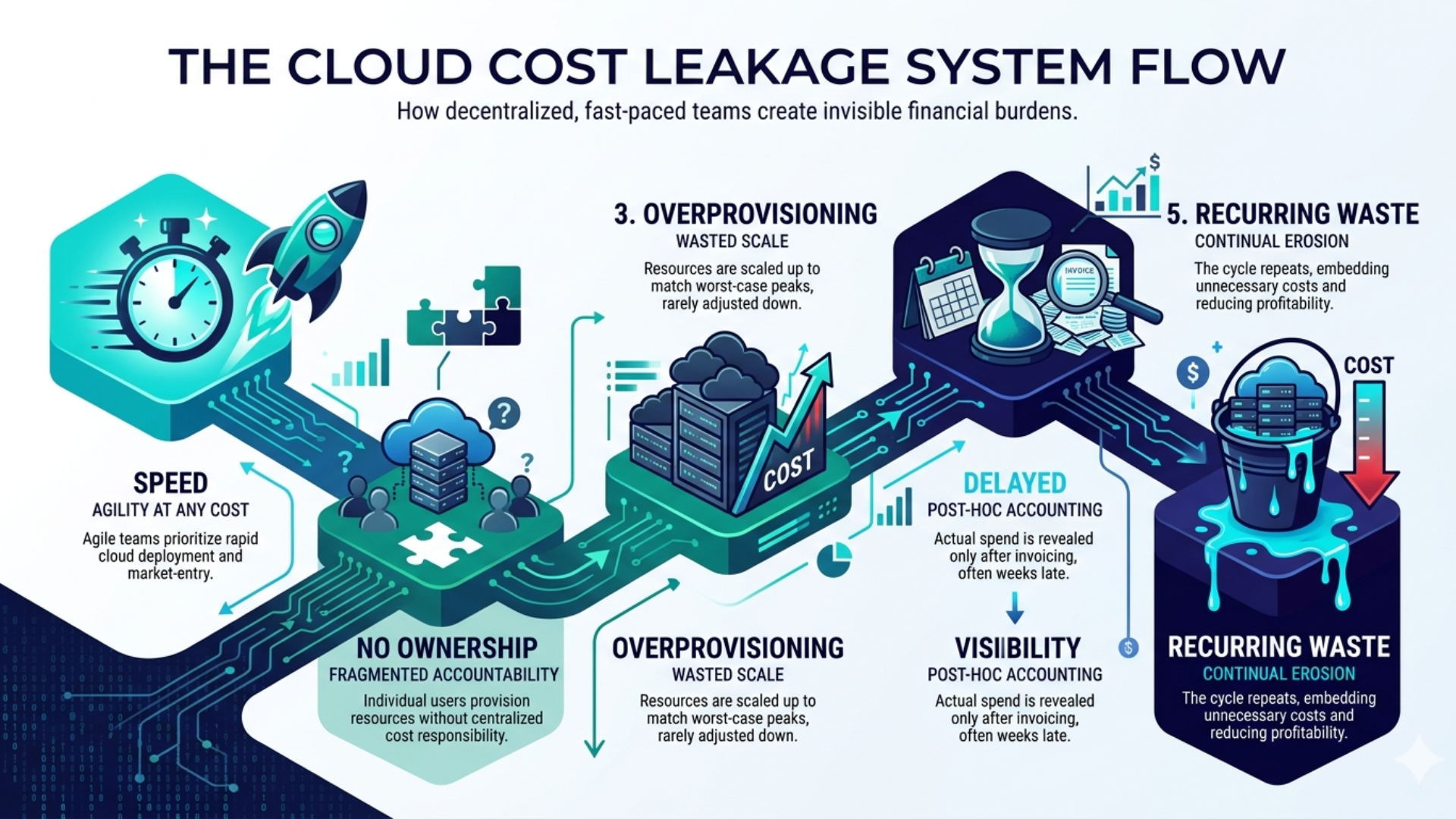
Not because they lack tools. Not because they lack awareness. But because cloud environments scale faster than the systems designed to control them. Infrastructure decisions are made in minutes. Cost implications unfold over months.
That lag is where inefficiency lives and where structured cloud cost optimization becomes critical.
If your cloud costs are increasing faster than your ability to explain them, the problem is not scaled. It is a structure.
→ Map your top 3 cloud cost leakages and expected savings in a 30-minute working session
Why do most cloud cost optimization efforts fail after early success
Because the problem is structural, not operational
Most organizations approach cloud cost management as a set of one-time actions, such as reducing idle resources, right-sizing instances, cut unused storage. These actions work. Temporarily. Costs return because the underlying system that created inefficiency remains unchanged.
Gartner predicts that over 60% of organizations will fail to achieve expected cloud ROI, not due to lack of effort, but due to lack of financial governance embedded into engineering workflows.
The structural mismatch most teams don’t address
Cloud operates on a consumption model. Engineering operates on a reliability model. Finance operates on a predictability model. These three are not aligned by default.
Engineers overprovision to avoid risk. Finance reacts after cost spikes. Leadership lacks real-time clarity. This creates a system where cost is visible, but not controllable.
Until ownership is embedded into this system, optimization remains temporary.
What is the real business cost of cloud inefficiency (Beyond the bill)
The first-order impact is financial. The second-order impact is strategic.
Cloud waste increases costs, but the larger issue is what it does to decision-making. According to McKinsey, organizations with low-cost visibility experience 15–20% slower decision cycles.
When cost becomes unclear, speed becomes a casualty. Product teams delay scaling. Finance introduces broad controls that restrict innovation. Engineering shifts from building to diagnosing. Over time, this creates friction, not because teams disagree, but because they are operating with different versions of reality.
Cloud cost reduction is not a cost-effective initiative. It is a coordination mechanism.
5 Proven Strategies to Slash Your Cloud Costs
These strategies work because they correct structural inefficiencies, not surface-level waste.
Strategy 1 — Cut Wasted Cloud Spend by Fixing How Your Infrastructure Provisioning Resources
Why Your Infrastructure Is Designed to Overbuild by Default
No engineering team provisions excess capacity out of carelessness. They do it because failure is unacceptable. Provisioning for peak load is a rational reliability decision, but cloud pricing is built for consumption, not reservation. That gap between what you provision and what you actually use is where your budget silently drains.
McKinsey estimates that continuous rightsizing alone delivers 15–25% in savings. The trigger point most engineering teams use: if a resource runs below 40% CPU utilization for 14 consecutive days, it is a rightsizing candidate. That single threshold, applied consistently across your estate, surfaces more savings than most tool audits.
Where Overprovisioning Hits Hardest, Inside Your Kubernetes Clusters
For teams running containerized workloads, Kubernetes is where overprovisioning compounds fastest and stays invisible the longest. According to Cast AI’s 2025 Kubernetes Cost Benchmark, 99% of Kubernetes clusters are overprovisioned, with average CPU utilization sitting at just 10% and memory utilization at 23%.
The reason is the same as above; developers set resource requests conservatively to avoid throttling and OOM kills. The consequence of under-requesting is immediate and painful. The consequence of over-requesting is invisible; it just inflates your bill quietly across every namespace, every cluster, every month. A 50-node cluster running at 12% average CPU utilization, at $300 per node per month, is spending $13,500 monthly on unused capacity before you count orphaned persistent volumes and over-provisioned node pools from deleted services still billing.
The most common waste patterns: memory overprovisioning in Java applications that never reach heap limits, CPU overallocation in web servers that spend most time waiting on I/O, and development workloads consuming production-grade resources during off-hours.
The fix starts with visibility, not configuration. Deploy OpenCost, CNCF-backed and open source, and run it for two weeks before touching anything. Kubecost extends this for multi-cluster environments. Vertical Pod Autoscaler then adjusts CPU and memory requests based on actual usage patterns. What you find will be uncomfortable. It will also be immediately actionable.
The shift that makes this stick: moving from capacity-based thinking to usage-based thinking. Infrastructure adapts dynamically to demand. Utilization becomes a tracked KPI. Idle capacity, whether on a VM or inside a Kubernetes node, is treated as a financial leak, not an engineering buffer.
Strategy 2 — Reduce Compute Costs by 40% by Moving Beyond On-Demand Pricing
On-Demand Pricing Is Costing You More Than You’ve Calculated
Most organizations default to on-demand pricing because commitment feels risky, no lock-in, no forecasting required. But reserved instances and savings plans reduce compute costs by 40–60% across AWS, Azure, and GCP. Staying on on-demand by default is not a neutral choice. It is an expensive one made by inertia.
The Sequencing That Turns Commitment Into Confident Savings
The hesitation is understandable; you cannot commit to what you cannot predict. But most enterprise workloads are more stable than their peak traffic suggests. The fix is sequencing, not guesswork.
Pull 90 days of usage history from AWS Cost Explorer or Azure Cost Management. Identify your steady-state floor, the compute you run regardless of traffic spikes. Commit reserved pricing only on that floor. Keep 20–30% on-demand for burst headroom.
The critical mistake most teams make: committing before rightsizing. Locking in waste at a discount is still waste, just at a lower unit price. Rightsize first, observe real consumption for 60–90 days, then commit to reservations that match your actual baseline. This sequencing protects you from controlling costs on paper while still overspending in practice.
Azure cost optimization and commitment strategy is a CTO-level decision not a procurement one.
👉 https://kansoftware.com/aws-vs-azure-vs-gcp-best-cloud-platform-for-enterprises/
Strategy 3 — Build a Governance System That Makes Cost Optimization Stick
Why Buying More Tools Without Governance Is Just Expensive Guesswork
Most CTOs invest in cloud cost optimization tools, expecting automation. What they get is dashboards. Dashboards surface information, but do not enforce action. The spending continues. The dashboard updates. Nothing changes.
The real problem is organizational. Engineering is rewarded for uptime and delivery speed. Overprovisioning is rational self-protection. Finance wants predictable numbers cloud’s consumption model makes that structurally impossible without governance. Leadership wants a single number; they receive a dashboard with 200 metrics and no clear owner.
Tools do not resolve this. Governance does.
The Governance Structure That Makes Cost Ownership Stick Across Every Team
Effective cloud financial management does not require a dedicated FinOps team to start. It requires a minimum viable structure that embeds ownership directly into how teams operate.
According to the FinOps Foundation’s 2026 State of FinOps report, organizations with C-suite engagement in cost governance show 2–4x more influence over cloud decisions than those operating at the director level alone.
The structure that works for SMEs: mandatory resource tagging enforced at the CI/CD pipeline level, no tag, no deployment. A named cost owner per engineering team, not a shared responsibility spread across all of them. A monthly 30-minute cost review that engineering leads attend alongside finance, not a finance-only exercise. With this structure, cloud financial management becomes systematic and self-reinforcing. Without it, every optimization effort reverts the moment the next sprint begins.

Strategy 4 — Recover 20% of Your Cloud Budget From Environments Nobody Is Watching
Non-Production Environments Run All Night. Your Team Doesn’t.
Dev, staging, and QA environments are treated as low-risk infrastructure. They are not low-cost. Gartner estimates 15–20% of total cloud spend sits in non-production environments, most of it running 168 hours a week for a team that works 45.
That means you are paying for 123 hours of idle compute every week, per environment, across every team that has ever spun one up and not scheduled it down.
The Automation Playbook That Eliminates Idle Environment Spend
The resistance to fixing this is cultural, not technical. Developers associate “off” with “lost work.” The answer is not to negotiate, it is to automate so the question never comes up.
AWS Instance Scheduler handles start/stop schedules via resource tags and takes an afternoon to implement. Azure Automation provides the same capability for Azure environments. For teams running containerized workloads, ephemeral environments eliminate the problem at the root, spun up by pull requests, torn down on merge, and never idle by design. Done right, this approach cuts development infrastructure costs by 60–70%.
Storage is the other half of the equation. Environments going to sleep do not eliminate orphaned snapshots, persistent volumes, and objects sitting in premium storage tiers from environments that no longer exist. Audit and automate cleanup. The savings are immediate, and the risk to production is zero.
Strategy 5 — Unify Multi-Cloud Visibility and Stop Paying for Fragmentation
How Ungoverned Multi-Cloud Quietly Becomes Your Biggest Cost Leak
Most SME tech companies do not decide to go multi-cloud. They drift into it, one team picks AWS, another uses Azure because enterprise credits were included, and GCP comes in for BigQuery or ML workloads. Before long, three billing consoles exist, three tagging schemas diverge, and reserved instance coverage becomes a separate guessing game per provider.
IDC reports that over 70% of enterprises operate in multi-cloud environments, but fewer than 30% manage them centrally. The cost of that gap is not just duplicated resources; it is the absence of a single source of truth that makes every optimization decision slower and less confident.
The Visibility and Tooling Framework That Brings Multi-Cloud Under Control
Unifying multi-cloud cost visibility is a function of spend maturity, not tool preference. If you are spending under $50K per month across providers, native tools AWS Cost Explorer, Azure Cost Management, GCP Cost Tools, combined with a consistent tagging schema, get you 80% of the way there. Above $100K per month across two or more providers, a dedicated cloud cost management platform pays for itself quickly. Most are priced at 2–3% of managed cloud spend. If they recover 20% waste, you are net positive within two billing cycles.
The governance layer matters more than the tool you choose. Tagging policies, cost ownership, and centralized reporting must be established before the tool is deployed, not after. A platform layered on top of ungoverned infrastructure produces more sophisticated reports of the same fragmentation.
Can AI actually improve cloud cost optimization outcomes

AI changes speed, not fundamentals
AI enables real-time anomaly detection, predictive cost modeling, and automated rightsizing recommendations. Organizations with mature FinOps practices and AI-driven cloud optimization consistently reduce cloud costs by 25–30%. For an SME spending $80K/month, that is $24K/month recovered, and the tooling costs a fraction of that.
AWS Compute Optimizer and Azure Advisor use machine learning to analyze utilization patterns and recommend instance changes. AWS cost optimization using generative AI goes further — natural language querying of cost data, automated root cause analysis of spend spikes, and proactive governance before engineers can provision unauthorized resources.
But AI does not fix broken systems
If your tagging is inconsistent, AI recommendations are inaccurate. If your teams do not own cost outcomes, AI alerts go unactioned. If governance does not exist, AI adds sophisticated dashboards on top of chaos.
The sequencing is non-negotiable: structure first, AI second. Gartner estimates 10–20% additional efficiency gains with AI-enabled FinOps, but only when governance already exists underneath it.
What does optimized cloud architecture actually look like?

The shift is not technical. It is operational.
In optimized environments, cost is visible at workload levels. Ownership is embedded in teams. Optimization is continuous. Decisions are faster and more confident. This is not a tooling upgrade; it is a shift in how the cloud is managed as a business resource.
What does a high-performing cloud cost optimization model look like
The 4-layer model that sustains cost efficiency
| Layer | What It Changes |
| Visibility | Eliminates blind spots |
| Ownership | Creates accountability |
| Automation | Reduces manual effort |
| Governance | Sustains results |
Where Kansoft fits into this
Most organizations know what to fix. Execution is where they struggle. Kansoft works at this execution layer, identifying hidden cost leakages, building tagging and governance systems, rightsizing Kubernetes clusters, automating non-production schedules, and aligning engineering and finance around a shared view of cost.
This is why cost reduction becomes visible within weeks, not quarters.
The real risk is not overspending. It is a delayed action.
Cloud inefficiency compounds. Every month of delay increases complexity. Every quarter makes cloud optimization harder to execute cleanly.
Organizations that implement structured cloud cost optimization reduce 20–30% of their spending within 6–12 months. Others continue absorbing inefficiency as a cost of doing business.
The gap between knowing and acting is where most cloud costs are lost.



